Differences IDP vs OCR
Optical character recognition, OCR, should not be mistaken for IDP since OCR only deals with recognizing characters and converting them into text. OCR has no features or understanding what the text means or how it should be extracted.Market Growth
IDP market is expected to grow from 1.7 - 1.9 billion USD in 2023 to 17.2 - 19.3 billion USD in 2032 (CAGR 28.9% - 30.5%). That’s more than ten times the coming 10 years. References: Market.us and Fortune Business InsightsOur IDP Flow
The flow of the IDP engine is shown in the image below highlighing an annual report being processed.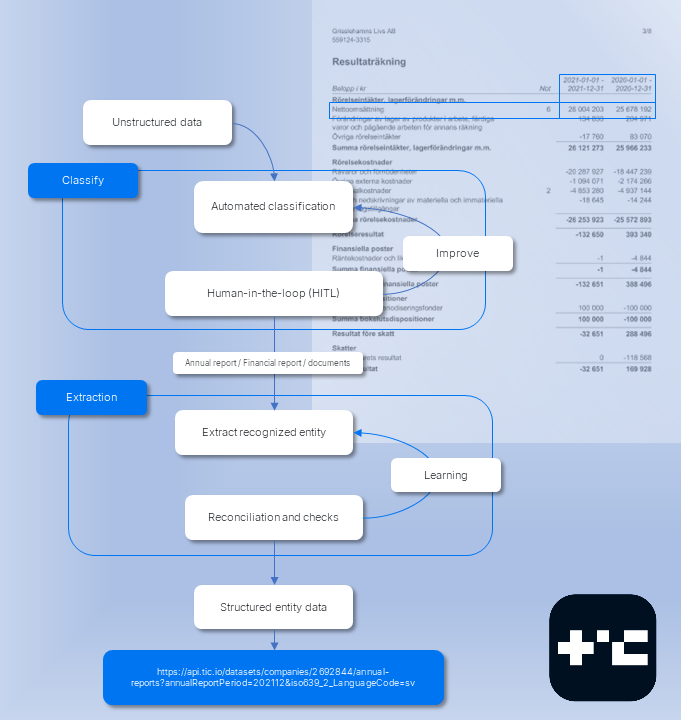
Computer Vision
To provide superior recognition we use computer vision along with algorithms to identify location of areas in the documents. Typical algorithms and filters used:Extraction and OCR
One of the techniques we use for extraction in images and documents is agglomerative hierarchical clustering (AHC). The algorithm finds dissimilarities between data and outputs an hierarchical representation. Our OCR engine is based on Tesseract with a kind of recurrent neural network called long-short term memory (LSTM). We train our models continuously based on the data we typically process.Example
Step 1 - raw page
The following image shows a raw page that has been highlighted by the IDP engine. The blue marked areas are going to be removed by the preprocessing system such as punch holes, stamps and page artifacts. Pages will be automatically rotated, deskewed and cleaned. Text blocks and characters are enhanced.
Step 2 - post processed page
The following image shows the same page but post processed by the set of instructions to determine the locations of meaningful data.
Step 3 - determine data locations
The following image shows the IDP engine locating areas of data subject for extraction.
Step 4 - extract to entities and run NLP
The final step is to extract the data by intepreting the context through the use of natural language processing (NLP). The data is then exposed in the API by a simple request:cURL
Response